Tablica napisów służy do odwzorowywania kolejnych liczb całkowitych (typu int) w zbiór napisów (typu char []) i napisów w kolejne liczby całkowite. Pierwsze z powyższych odwzorowań łatwo zaimplementować jako tablicę napisów (dokładniej: wskaźników do napisów lub jeszcze lepiej -- liczb całkowitych określających przesunięcie napisów w przechowującym je buforze). Jednak dużo trudniej jest napisać efektywną implementację odwzorowania napisów w kolejne liczby całkowite. Naszym celem będzie napisanie takiej implementacji tablicy napisów, która zagwarantuje praktycznie stały czas wyznaczania każdego z interesujących nas odwzorowań. Innymi słowy chcemy, aby czas wyliczania odwzorowania typu int w char [] i char [] w int był, średnio biorąc, niezależny od ilości napisów, faktycznie przechowywanych w tablicy (oczywiście w ramach pewnych rozsądnych ograniczeń na ich ilość). Używając żargonu matematycznego można nasze oczekiwania sformułować następująco: chcemy, aby czasy wyznaczania napisu, przyporządkowanego liczbie całkowitej, oraz liczby całkowitej, przyporządkowanej napisowi, był "rzędu O(1)".
Zwróćmy uwagę na to, że bodaj najprostsza implementacja tablicy napisów polega na zapisaniu par "napis-liczba" na specjalnej liście; w celu znalezienia liczby całkowitej odpowiadającej danemu napisowi przeszukuje się tę listę aż do znalezienia w niej napisu, który chcemy odwzorować na liczbę całkowitą. Czas realizacji takiego algorytm rośnie proporcjonalnie do ilości napisów, przechowywanych w tablicy (mówimy, że czas ten jest rzędu O(N)). Jednak stosując odpowiednią strukturę danych -- tablicę mieszającą -- czas odwzorowania napisu w liczbę można skrócić do praktycznie stałej wielkości. Sposób wykorzystania tablicy mieszającej do napisania efektywnej implementacji tablicy napisów przedstawimy w kolejnym paragrafie.
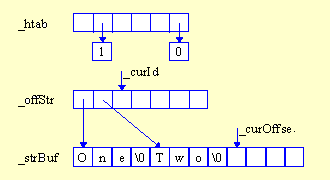
Mając wytyczony cel -- stworzenie szybkiej implementacji -- przystępujemy do projektowania tablicy napisów. Ponieważ chcemy mieć możliwość dodawania do niej wielu nowych danych, musi ona posługiwać się dużym buforem, zdolnym do przechowania naprawdę wielu napisów. Taki bufor zaimplementujemy jako osobną klasę StringBuffer. Obiekty tej klasy będą przechowywać napisy i informować, poprzez metodę GetOffset, o położeniu napisu w swoim wewnętrznym buforze _buf. Napisy umieszczane są w tej tablicy kolejno, jeden bezpośrednio po drugim. Informacja o położeniu napisu w tablicy reprezentowana jest poprzez indeks pierwszego znaku napisu, zwany w tym przypadku przesunięciem (ang. offset). Indeksy zapisane są w kolejnej strukturze danych -- tablicy indeksów _offStr, która odwzorowuje kolejne liczby naturalne w indeksy napisów. W ten sposób każdemu napisowi odpowiada pewna liczba całkowita, która po prostu jest indeksem do przesunięcia w tablicy napisów, a temu przesunięciu odpowiada pewna kolejna liczba porządkowa (0,1,2,...), którą nazywać będziemy identyfikatorem napisu.
Jak się już wkrótce przekonamy, podczas dodawania do tablicy nowego napisu musimy także dokonać odpowiedniego wpisu w kolejnej strukturze danych -- w tzw. tablicy mieszającej (ang. hash table). Powód wprowadzenia i zasady działania tablicy mieszającej przedstawimy w kolejnym paragrafie; na razie przyjmijmy, że jest to swoista czarna skrzynka, odwzorowująca napisy w krótkie listy liczb całkowitych.
const int idNotFound = -1;
const int maxStrings = 100;
// Klasa StringTable odwzorowuje napisy w liczby całkowite,
// a liczby całkowite w napisy
class StringTable
{
public:
StringTable ();
int ForceAdd (char const * str);
int Find (char const * str) const;
char const * GetString (int id) const;
private:
HTable _htab; // napis -> krótka lista liczb całkowitych
int _offStr [maxStrings]; // liczba całkowita -> przesunięcie ("offset")
int _curId;
StringBuffer _strBuf; // przesunięcie (tzw. "offset") -> napis
};
|
Napis, odpowiadający danemu identyfikatorowi, uzyskujemy z tablicy napisów za pośrednictwem metody GetString; identyfikator, odpowiadający danemu napisowi, uzyskujemy poprzez metodę Find; natomiast metoda ForceAdd służy do bezwarunkowego dodawania nowych napisów (bez sprawdzania, czy nie jest on duplikatem jakiegoś napisu, zapisanego już w tablicy napisów).
Rysunek 11. Tablica mieszająca _htab przechowuje indeksy do tablicy przesunięć _offStr, która z kolei przechowuje indeksy do bufora napisów _strBuf, który przechowuje napisy.
StringTable::StringTable ()
: _curId (0)
{}
int StringTable::ForceAdd (char const * str)
{
int len = strlen (str);
// czy w buforze jest jeszcze miejsce na kolejny napis?
if (_curId == maxStrings || !_strBuf.WillFit (len))
{
return idNotFound;
}
// zapisujemy info o miejscu, w którym przechowywany jest napis str
_offStr [_curId] = _strBuf.GetOffset ();
_strBuf.Add (str);
// dodajemy do tablicy mieszającej info o odwzorowaniu str w _curId
_htab.Add (str, _curId);
++_curId;
return _curId - 1;
}
|
Tablica mieszająca (która wciąż jest dla nas czarną skrzynką) zwraca krótką listę liczb całkowitych. Jedna z nich jest identyfikatorem danego napisu. Listę tę przeglądamy w poszukiwaniu właściwego identyfikatora.
int StringTable::Find (char const * str) const
{
// Z tablicy mieszającej pobieramy krótką listę liczb całkowitych
List const & list = _htab.Find (str);
// Przeglądamy kolejne elementy listy
for (Link const * pLink = list.GetHead ();
pLink != 0;
pLink = pLink->Next ())
{
int id = pLink->Id ();
int offStr = _offStr [id];
if (_strBuf.IsEqual (offStr, str))
return id;
}
return idNotFound;
}
// f-cja GetString odwzorowuje liczbę całkowitą id w napis.
// nie sprawdza się poprawności parametru id
char const * StringTable::GetString (int id) const
{
assert (id >= 0);
assert (id < _curId);
int offStr = _offStr [id];
return _strBuf.GetString (offStr);
}
|
Nasz bufor napisów zaimplementowano jako tablicę znaków, którą nazwiemy _buf. Będziemy zapisywać w niej kolejne standardowe napisy języków C i C++ (ciągi znaków zakończone bajtem zerowym), o ile tylko będzie w niej wystarczająco dużo miejsca. Składowa _curOffset jest indeksem do tablicy _buf, a jej wartość jest zawsze równa pierwszemu wolnemu znakowi tablicy, począwszy od którego możemy zapisać w niej kolejny napis.
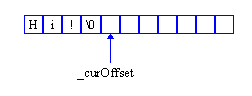
Rysunek 12. Bieżące przesunięcie (_curOffset) w buforze napisów (StringBuffer).
Oczywiście początkowo składowej tej przypisujemy wartość zero -- dzięki temu pierwszy napis zapisany zostanie na początku bufora. Zanim w buforze zapiszemy nowy napis musimy się upewnić, że zmieści się on w wolnej przestrzeni bufora. Umieszczanie w buforze kolejnego napisu polega na skopiowaniu go do miejsca, wskazywanego przez zmienną _curOffset i powiększenie wartości tej zmiennej tak, by wskazywała na znak znajdujący się bezpośrednio za bajtem zerowym skopiowanego napisu. Funkcja składowa GetOffset zwraca wartość składowej _currOffset tuż przed skopiowaniem napisu; można się nią później posługiwać w celu odczytania z bufora napisu, który za chwilę zostanie doń dopisany. Metoda IsEqual porównuje napis, rozpoczynający się od znaku o numerze offStr z napisem str, a metoda GetString zwraca (jako wskaźnik do stałej) napis, rozpoczynający się od znaku o numerze offStr.
const int maxBufSize=500;
class StringBuffer
{
public:
StringBuffer () : _curOffset (0)
{ }
bool WillFit (int len) const
{
return _curOffset + len + 1 < maxBufSize;
}
void Add (char const * str)
{
// strcpy (_buf + _curOffset, str);
strcpy (&_buf [_curOffset], str);
_curOffset += strlen (str) + 1;
}
int GetOffset () const
{
return _curOffset;
}
bool IsEqual (int offStr, char const * str) const
{
// char const * strStored = _buf + offStr;
char const * strStored = &_strBuf [offStr];
// jeżeli napisy są takie same, funkcja strcmp zwraca 0
return strcmp (str, strStored) == 0;
}
char const * GetString (int offStr) const
{
//return _buf + offStr;
return &_buf [offStr];
}
private:
char _buf [maxBufSize];
int _curOffset;
};
|
Wskaźnik do określonego elementu tablicy można utworzyć na dwa sposoby. Pierwszy z nich polega na pobraniu adresu n-tego elementu:
p = &arr [n]; // adres n-tego elementu |
Drugi sposób polega na wykorzystaniu arytmetyki na wskaźnikach:
p = arr + n; // wskaźnik plus liczba całkowita |
Oba sposoby są poprawne i prowadzą do wygenerowania dokładnie takiego samego kodu maszynowego (w powyższym przykładzie instrukcje bazujące na reprezentacji wskaźnikowej umieszczono w komentarzach). Jednak moim zdaniem notacja tablicowa jest bardziej przejrzysta.
Implementując metodę Add, posłużyłem się specjalnym operatorem przypisania, +=. Służy on do dodania wartości wyrażenia, znajdującego się po jego prawej stronie, do zmiennej, znajdującej sie po jego lewej stronie. Na przykład instrukcja
n += i; |
jest równoważna instrukcji
n = n + i; |
Kod maszynowy, odpowiadający każdej z tych instrukcji, jest oczywiście taki sam (jednak pierwotnie operator += wprowadzono do C jako element ułatwiający optymalizację kodu maszynowego). Niemniej jednak taki skrócony zapis jest bardzo użyteczny -- trzeba się tylko do niego przyzwyczaić1.
W implementacji klasy StringBuffer posłużyliśmy się kilkoma funkcjami z biblioteki standardowej, służącymi do przetwarzania tablic znaków. Ich deklaracje znajdują się w pliku nagłówkowym cstring. Dokładny opis działania tych funkcji znajdzie Czytelnik w systemie pomocy swojego kompilatora.
a <<= 3; |
a = a << 3; |